
工种预测模型算法实践
工伤预防精准化是当前工伤保险制度的重要发展方向。工种识别模型结合大数据和人工智能技术,能够实现对工伤风险的动态监测和实时预警,从而提升工伤预防的科学性和有效性
工种预测模型所需文件大类主要分为输入文件和输出文件两部分
输入文件
(1)标注文件:描述具体标签与归类标签之间的映射关系,以及不同工种与标准工种的对应关系,采用Excel格式便于操作。
(2)推理配置文件:通过设定规则判断事故中的标准工种,并建立关键词与标准工种的映射关系,包含五个主要的推理表。
(3)修正后的事故标注文件:将非结构化文本信息转换为结构化数据,主要任务是标注工种和标准工种。
(4)待测试事故Excel文件:用于输入待分析的事故案例数据,以便后续的模型测试和分析。
输出文件
结果文件:记录模型对工种识别的输出结果,用于评估模型预测标准工种的准确性,并通过准确率衡量模型表现。文件命名解释:包括行业、corpus总量、时间戳、准确率和配置文件迭代次数等信息,有助于快速了解文件内容和模型表现。
输入文件—标注文件
标注文件用于定义【具体标签】与【归纳集合标签】及不同工种与标准工种之间的映射关系。它以Excel格式保存,确保每行代表一个唯一的映射关系,便于导入导出和集成。此文件对于将非结构化文本信息转换为结构化数据、提升模型的准确性和一致性至关重要。
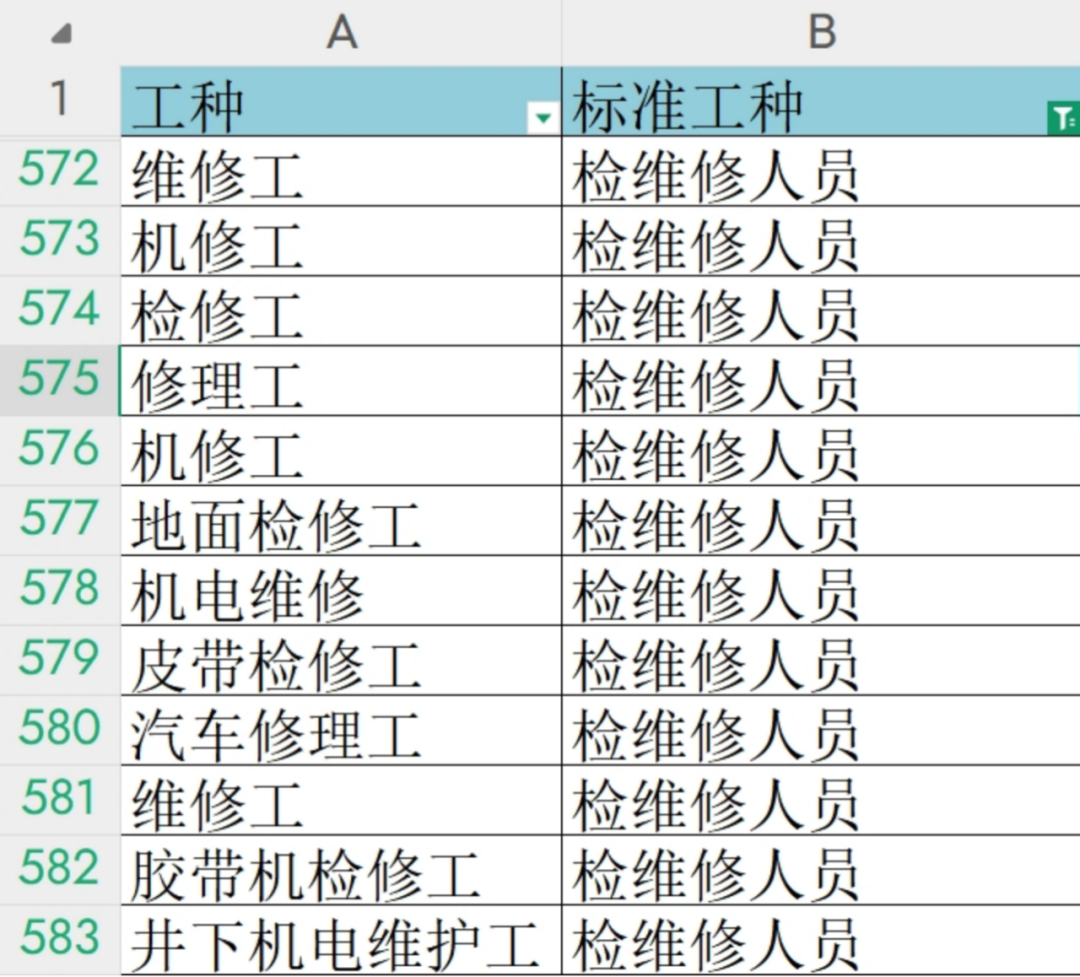
输入文件—推理配置文件
推理配置文件旨在通过一系列预设规则,从事故发生经过的描述中推断出标准工种。该文件建立了【工种】关键词和特殊格式与【标准工种】之间的映射关系,以确保准确识别。
主要核心组成部分:
• 模型推理配置:设定模型如何基于输入数据进行预测。
• 提问前综合推理:在用户提问之前,根据已有信息进行初步分析。
• 提问前关键字:定义了事故发生描述中的关键术语,帮助提前确定可能的标准工种。
• 提问后综合推理:在获得用户提供的具体信息后,进一步调整和确认工种分类。
• 兜底综合推理:当其它方法无法得出结论时使用的备用策略,确保每个事故描述都能得到一个合理的工种分类。
此配置文件通过结构化的规则集,增强了对非结构化文本的理解能力,从而提高了标准工种识别的准确性和效率。
输入文件—修正后的事故标注文件
数据标注概述
数据标注是将非结构化的文本信息(如事故发生经过)转换为结构化数据的过程,以便于后续分析和处理。主要任务是通过事故发生经过来标注工种和标准工种。以下是关键配置项及其扩展知识点:
1. 行业
• 说明: 分类不同行业类型,如采矿业、制造业等。
• 扩展: 行业分类有助于理解各行业的工种分布及特定安全风险,支持制定行业特定的安全规范。
2. 工种
• 说明: 指定具体工种,如采煤工、掘进工等。
• 扩展: 准确的工种标注对风险评估和预防措施至关重要,有助于识别高风险岗位并采取针对性培训和防护。
3. 事故发生经过
• 说明: 描述事故的具体经过,包含关键字和描述性信息。
• 扩展: 这一部分不仅是标注的基础,也是了解事故原因的关键,有助于发现安全隐患和管理漏洞。
4. 标准工种
• 说明: 根据事故发生经过提取的最准确工种描述。
• 扩展: 标准工种定义需基于权威标准或行业规范,确保所有标注员遵循统一标准以提高数据一致性。
5.数据标注最佳实践
• 一致性: 所有标注员使用相同标准,减少主观差异。
• 审核机制: 建立多层次审核机制,确保标注结果的准确性。
• 持续改进: 定期评估和更新标注指南,反映最新行业标准和技术进步。
• 反馈循环: 创建从模型预测到人工校正再到模型优化的闭环系统,提升模型性能。
• 培训与发展: 定期培训标注员,确保他们掌握最新技巧和工具。
6.数据标注的应用价值
• 风险管理: 识别高风险岗位,实施针对性安全管理。
• 政策制定: 支持政府和企业制定科学合理的安全生产政策。
• 学术研究: 提供宝贵资源,支持多个领域的研究。
• 技术开发: 构建高质量数据集,推动AI模型的发展。
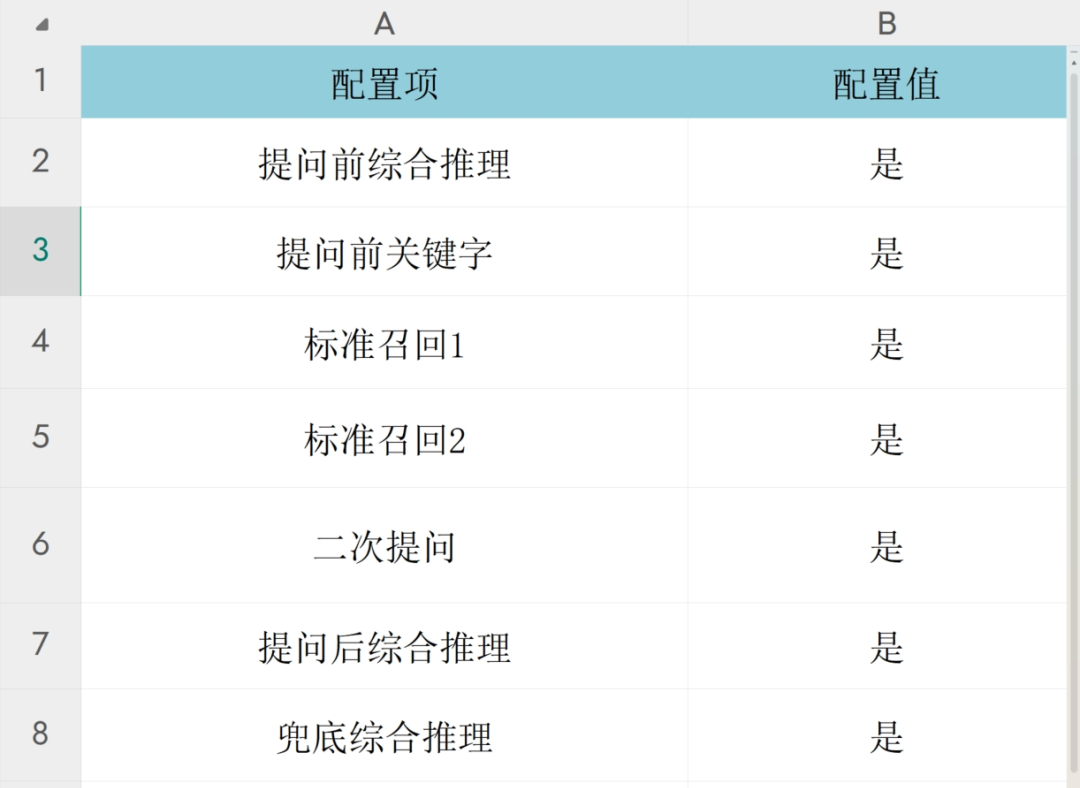
通过设定优先级属性,确保在多个关键字共存的情况下选择最合适的标注结果,提高工种标注的准确性和一致性。这种方法不仅提升了标注精度,还为后续的风险评估和安全管理提供了可靠的数据基础。
输入文件—待测试事故Excel文件
为了确保待测试事故Excel文件能够顺利进行工种标注和后续分析,文件格式必须包含以下关键列,特别是事故发生经过这一列。该列是工种标注和其他数据分析任务的基础。
输出文件-结果文件
目的
该文件记录了模型对工种识别的输出结果,旨在评估模型预测【标准工种】的准确性。通过对比模型预测结果与已知的标准工种,计算准确率,并不断优化模型表现。
模型分析字段
1. 事故发生经过(corpus)
• 说明: 记录事故发生的详细过程文本。
2. 标准工种
• 说明: 已知的、与事故相关的具体职业或工作类型。
模型输出字段
1. 模型标准工种
• 说明: 模型根据【事故发生经过】预测出的标准工种,目的是尽可能准确地匹配已有的【标准工种】。
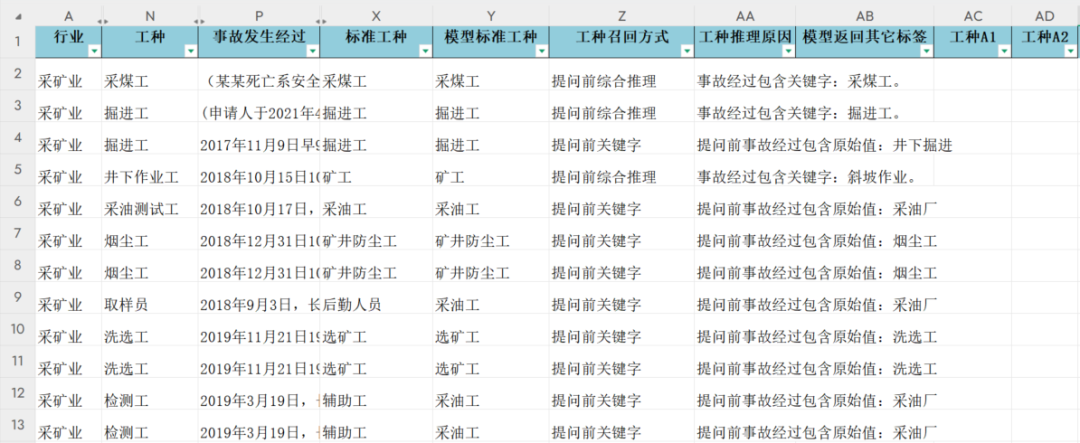
评估方法
• 统计模型预测正确的次数:将【模型标准工种】与【标准工种】进行比较,统计完全匹配的条目数。
• 计算准确率:用匹配正确的条目数除以总条目数,得出模型的准确率。
• 目标:使【标准工种】与【模型标准工种】相匹配的corpus数量最大化,提高模型的准确性。
数据文件命名规则
文件命名遵循特定格式,提供关于内容的重要信息:
行业/工种/采矿业_工种_9428条_1711101178_准确率92.08.xlsx_56.xlsx
• 行业: 例如“采矿业”,表示文件所属的行业类别。
• corpus总量: 例如“9428条”,表示该文件中包含的事故案例总数。
• 时间戳或唯一标识符: 例如“1711101178”,用于版本控制或追踪的时间戳。
• 准确率: 例如“92.08%”,表示模型正确标注【标准工种】的比例。
• 配置文件迭代次数: 例如“56次”,表明了模型训练或调整的轮次。
通过上述逻辑,确保输出文件不仅记录了模型的预测结果,还提供了评估模型性能的关键指标。这种结构化的命名方式和详细的字段设置,有助于高效管理和优化工种预测模型,确保其在不同行业中的应用效果。
